正则表达式-JavaScript
什么是正则表达式
正则表达式是用于匹配字符串中字符组合的模式。在 JavaScript中,正则表达式也是对象。
这些模式被用于RegExp的exec和test方法, 以及String的match、replace、search和split方法。
正则表达式存在于大部分的编程语言,就算是在写shell时也会不经意的用到正则。
比如大家最喜欢的rm -rf ./*,这里边的*就是正则的通配符,匹配任意字符。
在JavaScript也有正则表达式的实现,差不多就长这个样子:/\d/(匹配一个数字)。
个人认为正则所用到的地方还是很多的,比如模版字符的替换、解析URL,表单验证 等等一系列。
如果在Node.js中用处就更为多,比如请求头的解析、文件内容的批量替换以及写爬虫时候一定会遇到的解析HTML标签。
正则表达式在JavaScript中的实现
JavaScript中的语法
赘述那些特殊字符的作用并没有什么意义,浪费时间。
推荐MDN的文档:基础的正则表达式特殊字符
关于正则表达式,个人认为以下几个比较重要:
贪婪模式与非贪婪模式
P.S. 关于贪婪模式和非贪婪模式,发现有些地方会拿这样的例子:
1 | /.+/ // 贪婪模式 |
仅仅拿这样简单的例子来说的话,有点儿扯淡
1 | // 假设有这样的一个字符串 |
简单来说就是:
- 贪婪模式,能拿多少拿多少
- 非贪婪模式,能拿多少拿多少
捕获组
/123(\d+)0/ 括号中的被称之为捕获组。
捕获组有很多的作用,比如处理一些日期格式的转换。
1 | let date = '2017-11-21' |
又或者可以直接写在正则表达式中作为前边重复项的匹配。
1 | let template = 'hello helloworl' |
非捕获组
我们读取了一个文本文件,里边是一个名单列表
我们想要取出所有Stark的名字(但是并不想要姓氏,因为都叫Stark),我们就可以写这样的正则:
1 | let nameList = ` |
上边的(?=)就是非捕获组,意思就是规则会被命中,但是在结果中不会包含它。
比如我们想实现一个比较常用的功能,给数组添加千分位:
1 | function numberWithCommas (x = 0) { |
\B代表匹配一个非单词边界,也就是说,实际他并不会替换掉任何的元素。
其次,后边的非捕获组这么定义:存在三的倍数个数字(3、6、9),并且这些数字后边没有再跟着其他的数字。
因为在非捕获组中使用的是(\d{3})+,贪婪模式,所以就会尽可能多的去匹配。
如果传入字符串1234567,则第一次匹配的位置在1和2之间,第二次匹配的位置在4和5之间。
获得的最终字符串就是1,234,567
如何使用正则表达式
RegExp对象
创建RegExp对象有两种方式:
- 直接字面量的声明:
/\d/g - 通过构造函数进行创建:
new RegExp('\d', 'g')
RegExp对象提供了两个方法:
exec
方法执行传入一个字符串,然后对该字符串进行匹配,如果匹配失败则直接返回null
如果匹配成功则会返回一个数组:
1 | let reg = /([a-z])\d+/ |
P.S. 如果正则表达式有g标识,在每次执行完exec后,该正则对象的lastIndex值就会被改变,该值表示下次匹配的开始下标
1 | let reg = /([a-z])\d+/g |
test
方法用来检查正则是否能成功匹配该字符串
1 | let reg = /^Hello/ |
test方法一般来说多用在检索或者过滤的地方。
比如我们做一些筛选filter的操作,用test就是一个很好的选择。
1 | // 筛选出所有名字为 Niko的数据 |
String对象
除了
RegExp对象实现的一些方法外,String同样提供了一套方法供大家来使用。
search
传入一个正则表达式,并使用该表达式进行匹配;
如果匹配失败,则会返回-1
如果匹配成功,则会返回匹配开始的下标。
可以理解为是一个正则版的indexOf
1 | 'Hi Niko'.search(/Niko/) // => 3 |
split
split方法应该是比较常用的,用得最多的估计就是[].split(',')了。。
然而这个参数也是可以塞进去一个正则表达式的。
1 | '1,2|3'.split(/,|\|/) // => [1, 2, 3] |
该条规则会匹配,,但是,后边还有一个限定条件,那就是绝对不能出现数字+,的组合并且以一个]结尾。
这样就会使[4,5,6]里边的,不被匹配到。
match
match方法用来检索字符串,并返回匹配的结果。
如果正则没有添加g标识的话,返回值与exec类似。
但是如果添加了g标识,则会返回一个数组,数组的item为满足匹配条件的子串。
这将会无视掉所有的捕获组。
拿上边的那个解析HTML来说
1 | let html = '<p><span>text1</span><span>text2</span></p>' |
replace
replace应该是与正则有关的应用最多的一个函数。
最简单的模版引擎可以基于replace来做。
日期格式转换也可以通过replace来做。
甚至match的功能也可以通过replace来实现(虽说代码会看起来很丑)
replace接收两个参数replace(str|regexp, newStr|callback)
第一个参数可以是一个字符串 也可以是一个正则表达式,转换规则同上几个方法。
第二个参数却是可以传入一个字符串,也可以传入一个回调函数。
当传入字符串时,会将正则所匹配到的字串替换为该字符串。
当传入回调函数时,则会在匹配到子串时调用该回调,回调函数的返回值会替换被匹配到的子串。
1 | 'Hi: Jhon'.replace(/Hi:\s(\w+)/g, 'Hi: $1 Snow') // => Hi: Jhon Snow |
一些全新的特性
前段时间看了下
ECMAScript 2018的一些草案,发现有些Stage 3的草案,其中有提到RegExp相关的,并在chrome上试验了一下,发现已经可以使用了。
Lookbehind assertions(应该可以叫做回溯引用吧)
同样也是一个非捕获组的语法定义
语法定义:
1 | let reg = /(?<=Pre)\w/ |
设置匹配串前边必须满足的一些条件,与(?=)正好相反,一前一后。
这个结合着(?=)使用简直是神器,还是说解析HTML的那个问题。
现在有了(?<=)以后,我们甚至可以直接通过一个match函数拿到HTML元素中的文本值了。
1 | let html = '<p><span>text1</span><span>text2</span></p>' |
Named capture groups(命名捕获组)
我们知道,()标识这一个捕获组,然后用的时候就是通过\1或者$1来使用。
这次草案中提到的命名捕获组,就是可以让你对()进行命名,在使用时候可以用接近变量的用法来调用。
语法定义:
1 | let reg = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/ |
在match的返回值中,我们会找到一个groups的key。
里边存储着所有的命名捕获组。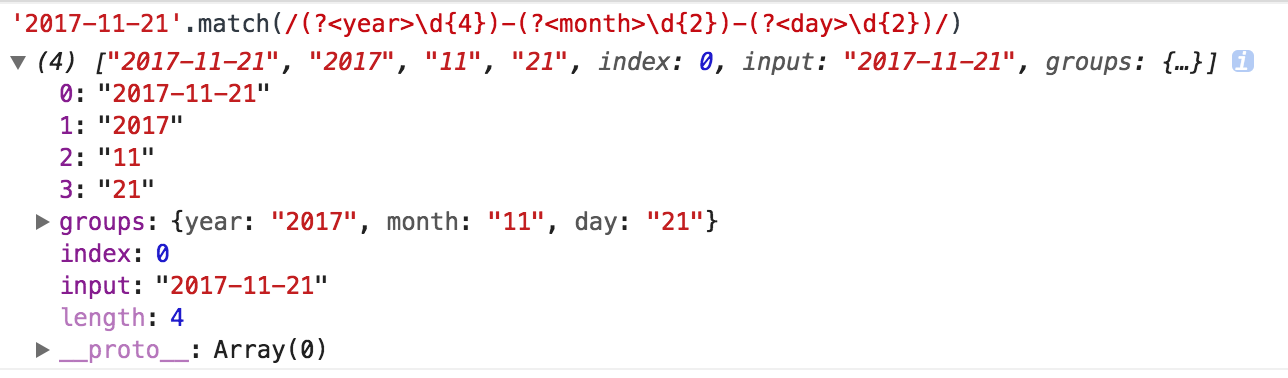

在replace中的用法
1 | let reg = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/ |
表达式中的反向引用
1 | let reg = /\d{4}-(?<month>\d{2})-\k<month>/ |