记一次Node项目的优化
这两天针对一个Node项目进行了一波代码层面的优化,从响应时间上看,是一次很显著的提升。
一个纯粹给客户端提供接口的服务,没有涉及到页面渲染相关。
背景
首先这个项目是一个几年前的项目了,期间一直在新增需求,导致代码逻辑变得也比较复杂,接口响应时长也在跟着上涨。
之前有过一次针对服务器环境方面的优化(node版本升级),确实性能提升不少,但是本着“青春在于作死”的理念,这次就从代码层面再进行一次优化。
相关环境
由于是一个几年前的项目,所以使用的是Express+co这样的。
因为早年Node.js版本为4.x,遂异步处理使用的是yield+generator这种方式进行的。
确实相对于一些更早的async.waterfall来说,代码可读性已经很高了。
关于数据存储方面,因为是一些实时性要求很高的数据,所以数据均来自Redis。Node.js版本由于前段时间的升级,现在为8.11.1,这让我们可以合理的使用一些新的语法来简化代码。
因为访问量一直在上涨,一些早年没有什么问题的代码在请求达到一定量级以后也会成为拖慢程序的原因之一,这次优化主要也是为了填这部分坑。
一些小提示
本次优化笔记,并不会有什么profile文件的展示。
我这次做优化也没有依赖于性能分析,只是简单的添加了接口的响应时长,汇总后进行对比得到的结果。(异步的写文件appendFile了开始结束的时间戳)
依据profile的优化可能会作为三期来进行。profile主要会用于查找内存泄漏、函数调用堆栈内存大小之类的问题,所以本次优化没有考虑profile的使用
而且我个人觉得贴那么几张内存快照没有任何意义(在本次优化中),不如拿出些实际的优化前后代码对比来得实在。
几个优化的地方
这里列出了在本次优化中涉及到的地方:
- 一些不太合理的数据结构(用的姿势有问题)
- 串行的异步代码(类似
callback地狱那种格式的)
数据结构相关的优化
这里说的结构都是与Redis相关的,基本上是指部分数据过滤的实现
过滤相关的主要体现在一些列表数据接口中,因为要根据业务逻辑进行一些过滤之类的操作:
- 过滤的参考来自于另一份生成好的数据集
- 过滤的参考来自于Redis
其实第一种数据也是通过Redis生成的。:)
过滤来自另一份数据源的优化
就像第一种情况,在代码中可能是类似这样的:
1 | let data1 = getData1() |
有两个列表,要保证第一个列表中的数据不会出现在第二个列表中
当然,这个最优的解决方案一定是服务端不进行处理,由客户端进行过滤,但是这样就失去了灵活性,而且很难去兼容旧版本
上面的代码在遍历data2中的每一个元素时,都会尝试遍历data1,然后再进行两者的对比。
这样做的缺点在于,每次都会重新生成一个迭代器,且因为判断的是id属性,每次都会去查找对象属性,所以我们对代码进行如下优化:
1 | // 在外层创建一个用于过滤的数组 |
这样我们在遍历data2时只是对filterData对象进行调用了includes进行查找,而不是每次都去生成一个新的迭代器。
当然,其实关于这一块还是有可以再优化的地方,因为我们上边创建的filterData其实是一个Array,这是一个List,使用includes,可以认为其时间复杂度为O(N)了,N为length。
所以我们可以尝试将上边的Array切换为Object或者Map对象。
因为后边两个都是属于hash结构的,对于这种结构的查找可以认为时间复杂度为O(1)了,有或者没有。
1 | let filterData = new Map() |
P.S. 跟同事讨论过这个问题,并做了一个测试脚本实验,证明了在针对大量数据进行判断item是否存在的操作时,Set和Array表现是最差的,而Map和Object基本持平。
关于来自Redis的过滤
关于这个的过滤,需要考虑优化的Redis数据结构一般是Set、SortedSet。
比如Set调用sismember来进行判断某个item是否存在,
或者是SortedSet调用zscore来判断某个item是否存在(是否有对应的score值)
这里就是需要权衡一下的地方了,如果我们在循环中用到了上述的两个方法。
是应该在循环外层直接获取所有的item,直接在内存中判断元素是否存在
还是在循环中依次调用Redis进行获取某个item是否存在呢?
这里有一点小建议可供参考
- 如果是
SortedSet,建议在循环中使用zscore进行判断(这个时间复杂度为O(1)) - 如果是
Set,如果已知的Set基数基本都会大于循环的次数,建议在循环中使用sismember进行判断
如果代码会循环很多次,而Set基数并不大,可以取出来放到循环外部使用(smembers时间复杂度为O(N),N为集合的基数)
而且,还有一点儿,网络传输成本也需要包含在我们权衡的范围内,因为像sismbers的返回值只是1|0,而smembers则会把整个集合都传输过来
关于Set两种实际的场景
- 如果现在有一个列表数据,需要针对某些省份进行过滤掉一些数据。
我们可以选择在循环外层取出集合中所有的值,然后在循环内部直接通过内存中的对象来判断过滤。 - 如果这个列表数据是要针对用户进行黑名单过滤的,考虑到有些用户可能会拉黑很多人,这个
Set的基数就很难估,这时候就建议使用循环内判断的方式了。
降低网络传输成本
杜绝Hash的滥用
确实,使用hgetall是一件非常省心的事情,不管Redis的这个Hash里边有什么,我都会获取到。
但是,这个确实会造成一些性能上的问题。
比如,我有一个Hash,数据结构如下:
1 | { |
现在在一个列表接口中需要用到这个hash中的name和age字段。
最省心的方法就是:
1 | let info = {} |
在hash很小的情况下,hgetall并不会对性能造成什么影响,
可是当我们的hash数量很大时,这样的hgetall就会造成很大的影响。
hgetall时间复杂度为O(N),N为hash的大小- 且不说上边的时间复杂度,我们实际仅用到了
name和age,而其他的值通过网络传输过来其实是一种浪费
所以我们需要对类似的代码进行修改:
1 | let results = await redisClient.hgetall('hash') |
P.S. 如果hash的item数量超过一定量以后会改变hash的存储结构,
此时使用hgetall性能会优于hmget,可以简单的理解为,20个以下的hmget都是没有问题的
异步代码相关的优化
从co开始,到现在的async、await,在Node.js中的异步编程就变得很清晰,我们可以将异步函数写成如下格式:
1 | async function func () { |
看起来是很舒服对吧?
你舒服了程序也舒服,程序只有在getData1获取到返回值以后才会去执行getData2的请求,然后又陷入了等待回调的过程中。
这个就是很常见的滥用异步函数的地方。将异步改为了串行,丧失了Node.js作为异步事件流的优势。
像这种类似的毫无相关的异步请求,一个建议:
能合并就合并,这个合并不是指让你去修改数据提供方的逻辑,而是要更好的去利用异步事件流的优势,同时注册多个异步事件。
1 | async function func () { |
这样的做法能够让getData1与getData2的请求同时发出去,并统一处理回调结果。
最理想的情况下,我们将所有的异步请求一并发出,然后等待返回结果。
然而一般来讲不太可能实现这样的,就像上边的几个例子,我们可能要在循环中调用sismember,亦或者我们的一个数据集依赖于另一个数据集的过滤。
这里就又是一个权衡取舍的地方了,就像本次优化的一个例子,有两份数据集,一个有固定长度的数据(个位数),第二个为不固定长度的数据。
第一个数据集在生成数据后会进行裁剪,保证长度为固定的个数。
第二个数据集长度则不固定,且需要根据第一个集合的元素进行过滤。
此时第一个集合的异步调用会占用很多的时间,而如果我们在第二个集合的数据获取中不依据第一份数据进行过滤的话,就会造成一些无效的请求(重复的数据获取)。
但是在对比了以后,还是觉得将两者改为并发性价比更高。
因为上边也提到了,第一个集合的数量大概是个位数,也就是说,第二个集合即使重复了,也不会重复很多数据,两者相比较,果断选择了并发。
在获取到两个数据集以后,在拿第一个集合去过滤第二个集合的数据。
如果两者异步执行的时间差不太多的话,这样的优化基本可以节省40%的时间成本(当然缺点就是数据提供方的压力会增大一倍)。
将串行改为并行带来的额外好处
如果串行执行多次异步操作,任何一个操作的缓慢都会导致整体时间的拉长。
而如果选择了并行多个异步代码,其中的一个操作时间过长,但是它可能在整个队列中不是最长的,所以说并不会影响到整体的时间。
后记
总体来说,本次优化在于以下几点:
- 合理利用数据结构(善用
hash结构来代替某些list) - 减少不必要的网络请求(
hgetalltohmget) - 将串行改为并行(拥抱异步事件)
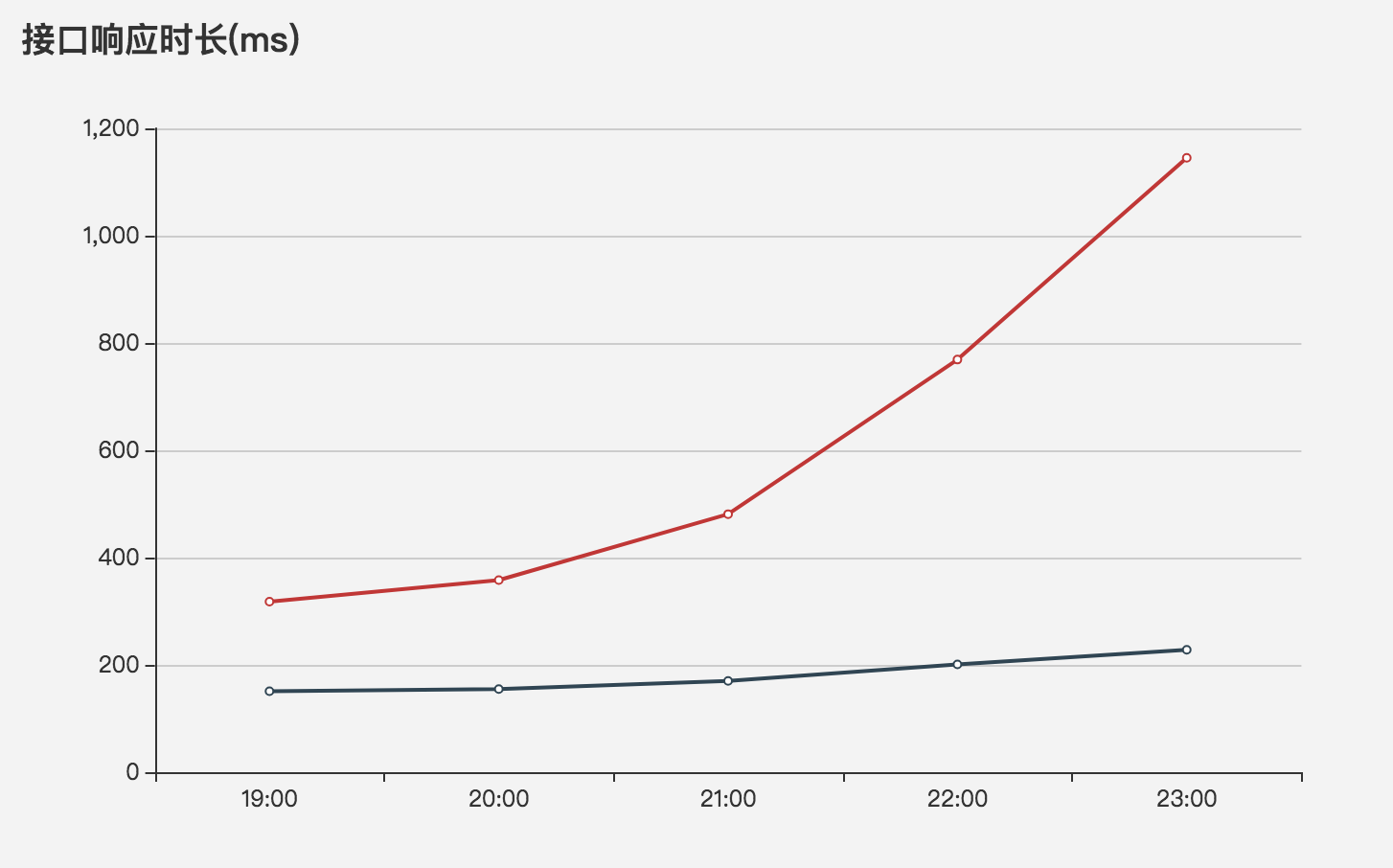
以及一个新鲜的刚出炉的接口响应时长对比图: