ioredis源码阅读[1]
上次针对 redis 的源码阅读涉及普通的 client,这次针对 cluster 模式下的 client 源码进行分析。
具体的源码路径就是在 lib/cluster 目录下了。
Cluster 实例化
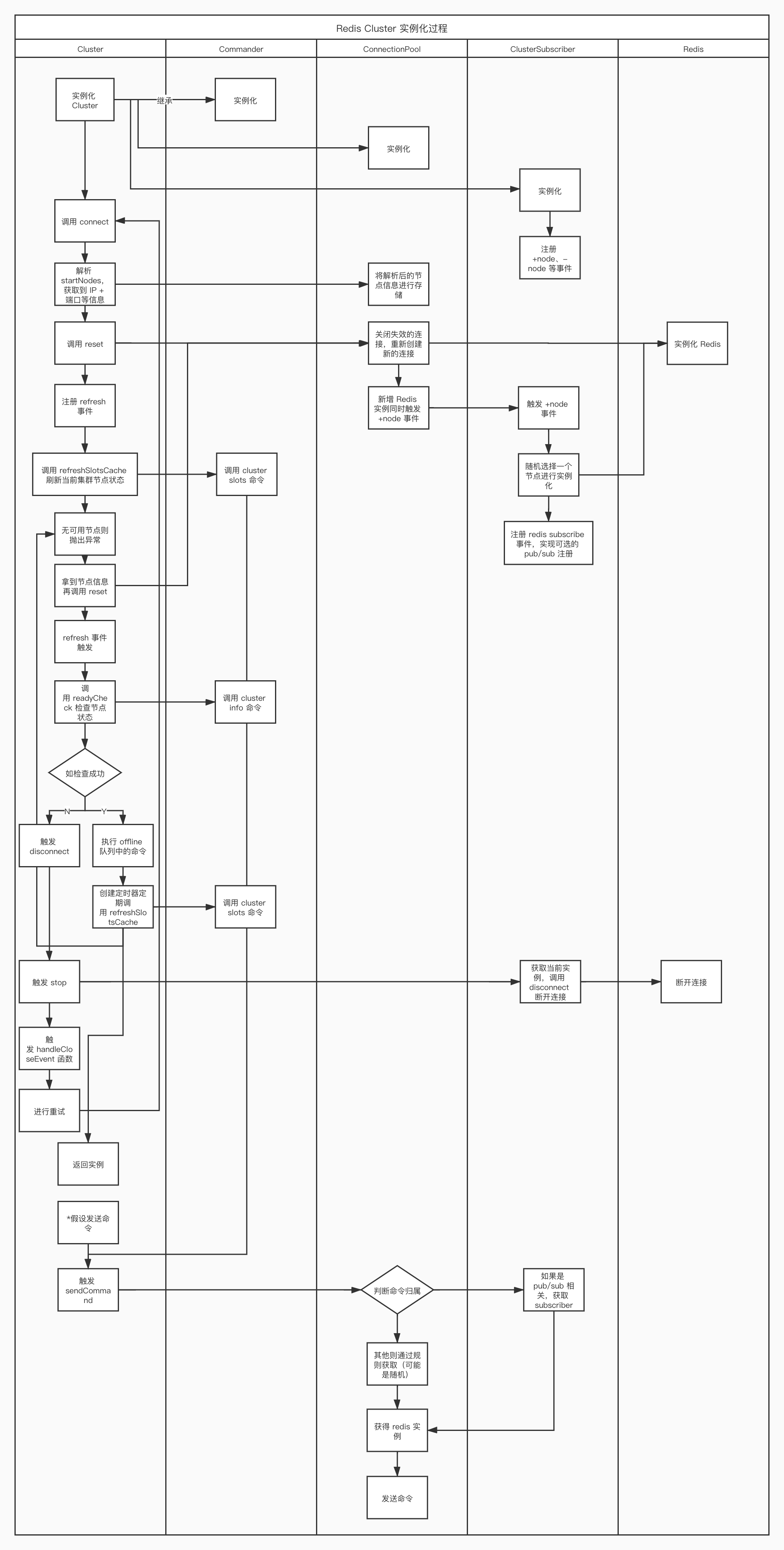
开门见山,我们使用 Cluster 模式最开始也是要进行实例化的,这里调用的代码位于 lib/cluster/index.ts:
1 | const { Cluster } = require('ioredis') |
从源码上来看,Cluster 预期接收两个参数,第一个是启动的节点集合 startNodes,第二个是一个可选的 options,
第一个参数是比较固定的,没有太多含义,而第二个参数可以传递很多配置,这个可以在 README 中找到(目前是 12 个参数): https://www.npmjs.com/package/ioredis#cluster
如果没有传入的话,则会有默认值来填充,但并不是所有的参数都会有默认值。
与 Redis Client 一样的处理逻辑,在构造函数中会 call 一下 Commander,随后还会实例化一个 ConnectionPool 对象,并将 options.redisOptions 传入进去。
代码位于 lib/cluster/ConnectionPool.ts
在实例化 ConnectionPool 的过程中并没有做什么实质性的操作,只是把 options.redisOptions 放到了一个 private 属性中。
随后在 Cluster 构造函数中注册了四个对应的事件,分别是 -node、+node、drain 和 nodeError,分别代表了 移除节点、增加节点、节点为空、节点出错。
是 ConnectionPool 自己实现的一些事件,后续会看到在哪里触发。
接下来实例化了一个 ClusterSubscriber 对象,并将上边实例化的 connectionPool 实例作为参数放了进去,并把 Cluster 实例的引用也传了进去。
实例化过程中做的事情也比较简单,就是监听了上边我们提到的 -node 与 +node 两个事件,在移除节点时,会判断是否存在 subscriber 属性,如果不存在则跳出,如果存在的话,会判断被移除的 key 是否等于当前 subscriber。
这里可以提一下 subscriber 究竟是什么,这个在下边的 selectSubscriber 函数中可以看到,就是实例化了一个 Redis Client,而实例化 Redis Client 所使用的参数,都是通过调用 connectionPool 的 getNodes 方法所拿到的,并随机挑选其中一个节点配置来进行实例化。
之后就会通过该 Redis Client 来调用两个命令,subscriber 与 psubscriber,这两个是用来实现 Pub/Sub 的,具体区别其实就是后者可以监听一个带有通配符的服务。
subscriber 与 psubscriber 的区别:https://redis.io/topics/pubsub
并在接收到数据以后,通过emit的方式转发给Cluster,后续 Cluster 模式下的 Pub/Sub 将会通过这里来进行数据的传递。
Connect
最后我们调用 connect 函数就完成了整个 Cluster 实例化的过程。
如果是开启了 lazyConnect 那么这里就直接修改实例状态为 wait,然后结束整个流程。
在 connect 时我们首先会解析 startNodes,拿到对应的 IP 和 端口等信息,然后会调用 reset 重置 connectionPool 中的实例,connectionPool 中会存储多个 IP+端口 的 Redis 实例引用,调用 reset 会把一些应该不存在的实例给关掉,然后把一些新增加的进行创建,复用已经存在的实例,同时在新增节点的时候会触发 ClusterSubscriber 的 +node 事件,如果此时是第一次触发,那么这时 ClusterSubscriber 才会真正的去创建用于 Pub/Sub 的 Redis 实例。
之后会注册一个 refresh 事件,在事件内部会调用 readyCheck,在这之前,则需要先去获取 Redis 节点的一些信息,这里是通过 getInfoFromNode 方法来实现的,内部会拿到一个 Redis 实例,并调用 duplicate 创建一个额外的实例,然后调用 cluster slots 命令来获取当前 Redis 集群服务状态,这里返回的数据会包含所有的节点 IP + 端口,同时包含某个节点的起始结束返回,具体的返回值如下:
1 | redis 127.0.0.1:6379> cluster slots |
转换成 JS 的数据大致是一个这样的结构:
1 | [ |
cluster slot 的描述:https://redis.io/commands/cluster-slots
在获取到这些真实的节点信息以后,会依据拿到的节点集合,再次调用 connectionPool 的 reset 方法,因为上次调用其实是使用的 startNode 传入的初始值,这里则会使用当前服务正在运行的数据进行一次替换。
在完成这一动作后,则会触发 refresh 事件,也就会进入下边的 readyCheck 环节,确保服务是可用的。
readyCheck
查看 readyCheck 的实现,主要也是通过调用 cluster info 命令来获取当前服务的状态。
在前文所讲处理 twemproxy 模式下的问题时,将 Redis Client 的 readyCheck 从 info 修改为了 ping 命令来实现,而这里,则没有进行修改,因为要注意的是,这里并不是 info 命令,而是 cluster 命令,只不过参数是 info。
Cluster 模块会使用 cluster info 命令中的 cluster_state 字段来作为检测的依据,数据会按照 k:v\nk:v\n 这种格式组合,所以我们会在代码中看到通过匹配换行来取得对应的字段,并通过截取的方式拿到具体的值。
不过针对这里的逻辑,我个人倒是觉得直接用正则匹配反而更简单一些,因为拿到参数的值并没有做一些额外的操作,仅仅是用来验证。
1 | private readyCheck(callback: CallbackFunction<void | "fail">): void { |
当我们发现 cluster info 中返回的数据为 fail 时,那么说明集群中的这个节点是一个不可用的状态,那么就会调用 disconnect 断开并进行重连。
在触发 disconnect 的时候,同时会关闭 ClusterSubscriber 中的实例,因为我们的连接已经要关闭了,那么也没有必要留着一个注册 Pub/Sub 的实例在这里了。
在这些操作完成之后,会进入 retry 的流程,这里其实就是按照某种逻辑重新调用了 connect 方法,再次执行前边所描述的逻辑。
针对整个流程画图表示大概是这样的:
sendCommand
在实例创建完毕后,那么下一步就会涉及到调用命令了。
在前边实例化过程中不可避免的也提到了一些 sendCommand 的事情,Redis 在实例化的过程中,会有一个状态的变更,而每次触发 sendCommand 实际上都会去检查那个状态,如果当前还没有建立好连接,那么这时的命令会被放入到 offlineQueue 中暂存的。
在 readyCheck 通过之后会按照顺序来调用这些命令。
当然,在 sendCommand 方法中也存在了对当前实例状态的判断,如果是 wait,那么可以认为实例开启了 lazyConnect 模式,这时会尝试与服务端建立连接。
同时在 sendCommand 中也会对命令进行判断,一些 Pub/Sub 对应的命令,比如 publish,会被转发到 ClusterSubscriber 对应的实例上去执行,而其他普通的命令则会放到 connectionPool 中去执行。
通过这样的方式将发布订阅与普通的命令进行了拆分。
同样,因为是 Cluster 模式,所以还会有主从之间的拆分逻辑,这个可以通过实例化 Redis Cluster 时传入的 scaleReads 参数来决定,默认的话是 master,可选的还有 all、slave 以及一个接收命令以及实例列表的自定义函数。
知识点来了
在 ioredis 中,默认情况下的配置是 master,这也就意味着所有的请求都会发送到 master 节点,这就意味着如果你为了提高读取的性能所创建的一些从库,__根本不会被访问到__。
详情见文档: https://www.npmjs.com/package/ioredis#user-content-read-write-splitting
如果想要使用从库,那么可以把 scaleReads 修改为 slave,但是不需要担心说一些会对数据库造成修改的命令发送到从库,在 sendCommand 中会针对所发送的命令进行检测,如果不是只读的命令,且 scaleReads 设置的不是 master 会强行覆盖为 master。
针对命令是否为只读的判断: https://github.com/luin/ioredis/blob/master/lib/cluster/index.ts#L599
然后关于那个自定义函数,其实就是需要自己根据 command 去评估究竟使用哪个(些)实例,然后把对应的实例返回出去。
最终,我们拿到了一个 Redis 实例,这时使用该 Redis 实例进行调用 sendCommand 即可。
然后后边的逻辑就和普通的 Redis 触发命令没有什么区别了。
总结
总的来看, 在 ioredis 的实现中 Redis Cluster 是作为一个 Redis 的扩展来做的,在很多地方都会看到 Redis 的存在,并且同样都会继承自 Command 实例,这就让用户在使用的过程中并没有太多的差异,只有在实例化时传入的参数不太一样,在调用各种 Redis 命令时则没有区别,而在 Cluster 中则内部调用了 Redis 的 sendCommand 完成了逻辑上的复用。