记一次 Node.js http 服务的排障记录
前言
最近我们团队接手了一个遗留项目,是由 Node.js 语言所编写的 HTTP 服务项目,项目大致逻辑是通过 Node.js 来实现一层代理逻辑,做流量的中转,并添加一些关键的埋点来展示请求记录(以及一些进阶的用法,篡改请求相关的数据,但与本次排障无关,便不赘述)。
刚接手的时候我们得到的情况是,这个项目因为内存泄漏和其他未知的原因,导致项目毕竟定时进行重启,否则用户使用时会感受到明显的延迟 or 服务直接不可用。
所以我们在一边进行人肉运维的同时,开始阅读源码,了解项目,分析问题的原因并尝试进行修复。
排查过程
该项目是有关键的指标埋点的,包括内存、CPU等指标,以及用户流量的数据统计,我们看到了两个比较重要的指标:
- 内存趋势
- Active Handle 的数量
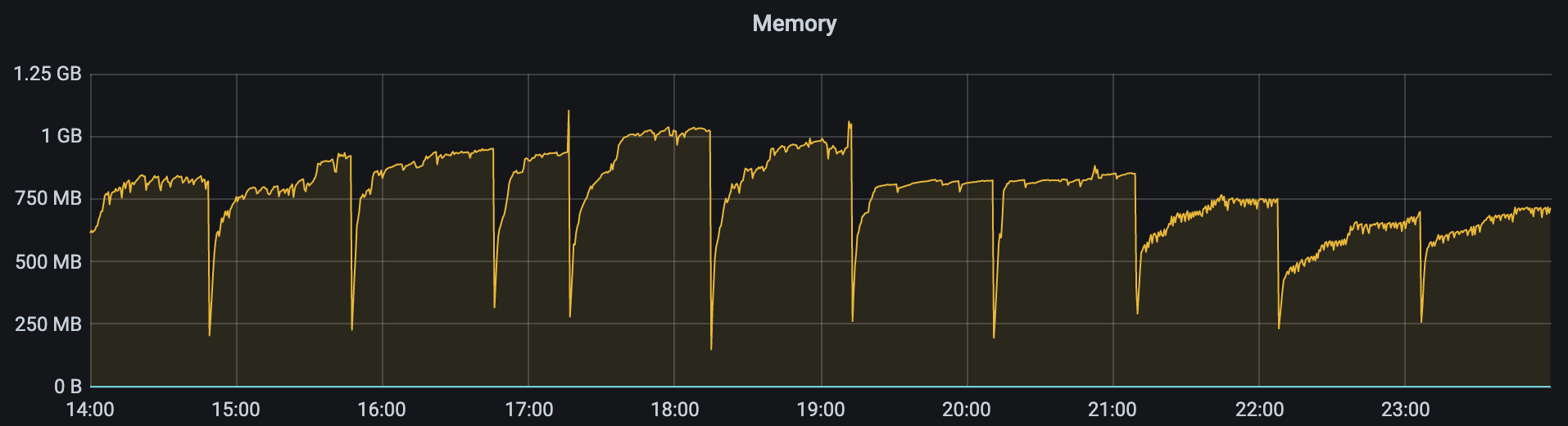
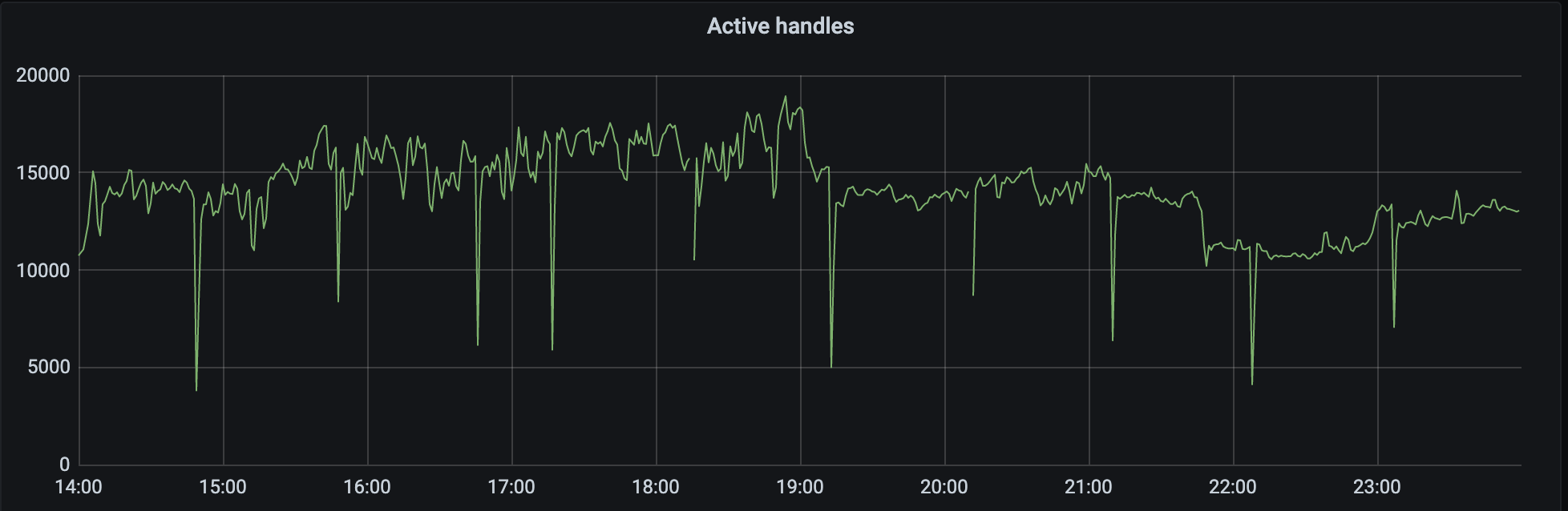
就像最初得到的信息一样,有内存泄漏的问题存在,而不到一个小时的指标断崖式下跌就是因为服务被重启导致的。
同样下边一个 Active Handle 指标也是波动非常的大,这里可以简单介绍一下 Active Handle 是什么,这个会延伸提到一个 Node.js 技术栈经常涉及到的一个关键词: Event Loop。
简单介绍 Event Loop
简单解释一下 Event Loop 的工作模式,如果我们有一个文件,写了这样的代码:
console.log('hello')
那么我们通过 node XXX 的方式运行该文件,运行完毕后进程就会退出了。
而如果我们写一个这样的文件:
console.log('hello')
setInterval(() => {}, 1e3)
再次通过 node XXX 的方式运行该文件,则终端会一直停留在该进程,并不会退出,因为我们创建了一个定时器,而定时器可以理解为是一个 Active Handle,而 Event Loop 的运行流程就是会执行所有的同步代码,然后检测是否存在 Active Handle,如果没有检测到则会直接退出,如有存在的 Handle 则会进入我们熟悉的 Event Loop。
我们可以通过一个非公开的 API 来获取到 Active Handle 的数量:
process._getActiveHandles()
console.log(process._getActiveHandles().length) // 0
如果通过 node XXX 的方式运行这样的代码,那么我们会得到一个 0,而如果我们直接通过 node 进入交互命令行,则会发现这个值为 2,这是因为交互式命令行会绑定 stdin 与 stdout,这也是为什么你会停留在交互式命令行环境,而非终端。
类似 process.nextTick、net.listen、fs.XXX 多种异步 API 都可以认为是一个 Active Handle,只要有类似的场景存在,进程就能一直在运行。
上边简单说明了一下 Active Handle 是什么,后边会提到为什么这个指标会帮助我们排查到问题。
分析问题
我们在看项目代码的过程中,发现该项目的核心逻辑是做流量的转发,而实现这一功能的方式是通过两个 Socket 互相绑定来做到的,具体代码:
export function pipeSocket(from: Socket, to: Socket) {
from.on('data', chunk => {
to.write(chunk)
})
from.on('close', () => {
to.destroy()
})
}
看似没啥毛病,不过结合着我们前边所看到的 active handle 数量非正常波动,我们有理由怀疑和这里有关。
同时我们在指标异常的时候在服务器上进行问题的排查,发现了一些端倪。
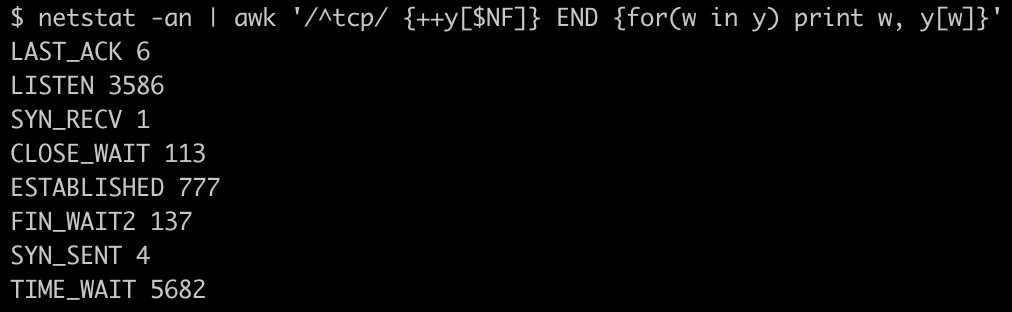
我们通过执行 netstat -an | awk '/^tcp/ {++y[$NF]} END {for(w in y) print w, y[w]}' 来查看当前连接区分类型的数量统计,得到了类似这样的结果:
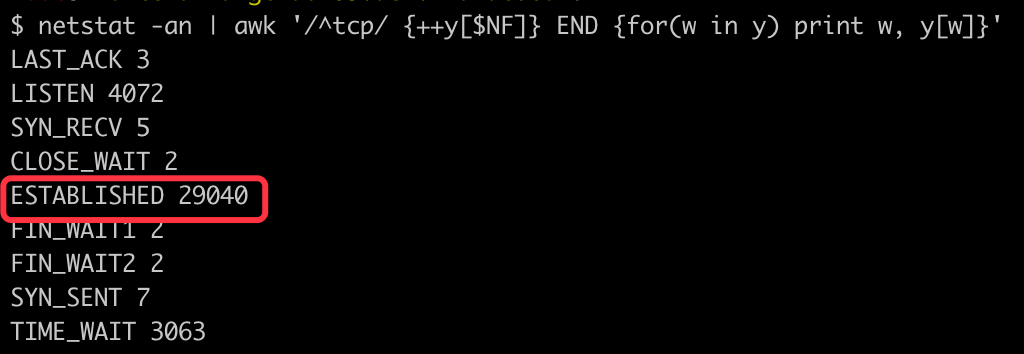
可以看到其中 ESTABLISHED 类型的数量非常多,这个其实与我最开始的猜测有差异,我本以为会是常见的 CLOSE_WAIT、TIME_WAIT 问题,没想到会是 ESTABLISHED 数量异常。
在 TCP 连接的状态定义中 ESTABLISHED 代表了一个已经建立成功的连接,可以理解为一个正常的数据传输状态:
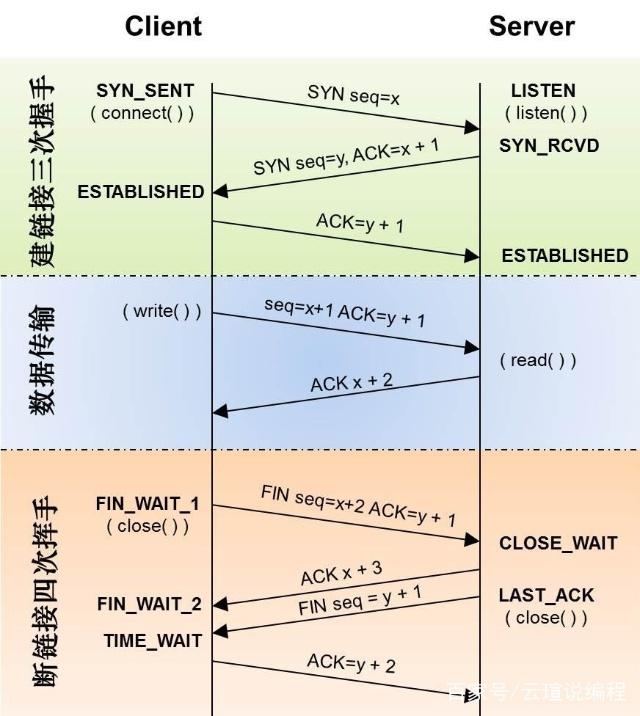
但是同时存在这么多的传输中的连接显然不是一个正常的状态,所以我们通过执行 netstat -nat|grep ESTABLISHED|awk '{print$5}'|awk -F : '{print$1}'|sort|uniq -c 来进一步查看究竟是哪些 IP 所占据的连接最多,果不其然发现是 127.0.0.1,这是因为该项目的代理逻辑就是通过转发到本地某个特定端口的服务来完成的,实际代理逻辑由该服务来提供。
因 IP 敏感性所以不贴图了。
大致情况就是查出来了大概几十条数据,而 127.0.0.1 一条数据对应的数量超过了 2W。
接下来我们针对 127.0.0.1 进行进一步的排查,我们要找出为什么会有这么多的连接处于一个传输中的状态,为什么这些连接没有被关闭。
所以我们通过执行 ss -aoen | grep '127.0.0.1' | grep 'ESTAB' | tail -n 10 来抽样得到前十个相关的 Socket 统计信息,在这里我们发现了一些端倪,在统计信息的最后一列详细信息中,我们发现好多 Socket 并没有超时设置。
这个就比较令人疑惑,因为我们系统其实是设置了 keep alive 的,如果对端数据已经不再传输,那么连接应该只会保留 2小时(我们系统设置的为 7200),按理说两个小时也不会产生如此数量的连接。
经过上边的 ss 命令得到的结果也帮我们更确定了一点,有 socket 没有正常释放,一直处于 ESTABLISHED 的状态,为了统计准确的数据,我们分别输入下边两条命令,按照是否包含 timer 来区分统计:
ss -aoen | grep '127.0.0.1' | grep 'ESTAB' | grep -v 'timer:' | wc -l # 28636
ss -aoen | grep '127.0.0.1' | grep 'ESTAB' | grep 'timer:' | wc -l # 115
数量差距非常可怕,我们再通过采样找到其中的几个 ss 端口号,通过 lsof -p <进程 ID> | grep <端口号> 的方式筛选查看该文件描述符的信息。
再拿到 FD 列的具体值,并通过 ll /proc/<端口号>/fd/<FD> 的方式查看到创建日期,发现半天前的都有,这肯定就超过了 keepalive 的检测时间。
依据上述信息,差不多是确定了问题出在哪。
修复问题
定位问题后我们开始着手修复,因为目标已经比较明确,找到那些没有设置 keepalive 的地方,并添加 keepalive。
这就又回到了前边比较关键的那个函数上:
export function pipeSocket(from: Socket, to: Socket) {
from.on('data', chunk => {
to.write(chunk)
})
from.on('close', () => {
to.destroy()
})
}
如之前所提到的 Active Handle,Socket 也是其中一种,因为涉及到一个连接的建立,所以我们通过前边的探索后第一时间聚焦到了这个函数上。
通过查看 net 模块的文档,我们发现默认 Socket 是不会添加 keepalive 的:https://nodejs.org/api/net.html#net_socket_setkeepalive_enable_initialdelay
所以简单的解决方法就是我们在函数内部添加 Socket 的 setKeepAlive 操作。
趁着我们已经在看 net 模块文档了,所以我们仔细研究了一下 Socket,发现不仅默认没有 keepalive,甚至说连 timeout 默认也是没有的。
顺带的我们也追加了 timeout 的处理,这是因为该项目用做代理服务,全局所有的请求都会过一遍服务,难免会有用户 偶尔、非主观、一不小心 访问到一些非法资源,这会导致该请求一直处于一个 pending 的状态,所以我们要添加 timeout 来防止这种情况的发生。
接下来再来说函数内部事件的处理,发现现有逻辑只处理了 close,但实际上 Socket 有着很多的事件,包括 error、end、timeout等。
而即便我们设置了 timeout,实际上 Socket 也不会自动关闭的,只是会触发 timeout 事件,真正的关闭需要我们手动执行。
而且目前在 close 事件中采用的是 destroy,而更推荐的做法则是使用 end,end 会发送 FIN 到对端,而 destroy 则会直接销毁当前连接,在事件触发上呢 end 会触发 end 与 close,而 destroy 只会触发 close。
所以经过我们上述的改动后,函数变成了这个样子:
export function pipeSocket(from: Socket, to: Socket) {
from.setTimeout(60 * 1e3)
from.setKeepAlive(true, 60 * 1e3)
from.on('data', chunk => {
to.write(chunk)
})
from.on('close', () => {
to.end()
})
from.on('error', () => {
to.end()
})
from.on('end', () => {
to.end()
})
from.on('timeout', () => {
from.destroy()
})
}
验证问题
将上述代码修改并提交后,试跑了一段时间,再次通过命令查看 TCP 连接数量:
ss -aoen | grep '127.0.0.1' | grep 'ESTAB' | grep -v 'timer:' | wc -l # 191
ss -aoen | grep '127.0.0.1' | grep 'ESTAB' | grep 'timer:' | wc -l # 261
再次通过 netstat -an | awk '/^tcp/ {++y[$NF]} END {for(w in y) print w, y[w]}' 验证 TCP 各个状态下的连接数量:
TIME_WAIT 虽说看着很多,但是与之前的 ESTABLISHED 不同,它并非一直存在,因为请求多,所以会一直关闭、创建 循环,所以每次输入命令时都会看到很多 TIME_WAIT 状态的,这是 TCP 连接关闭的正常状态。
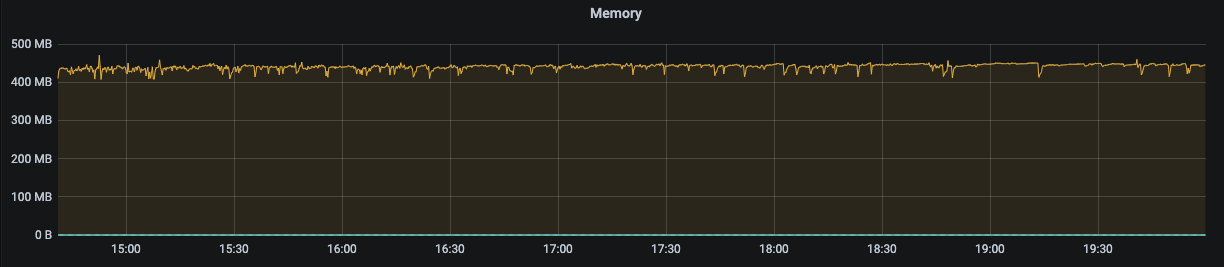
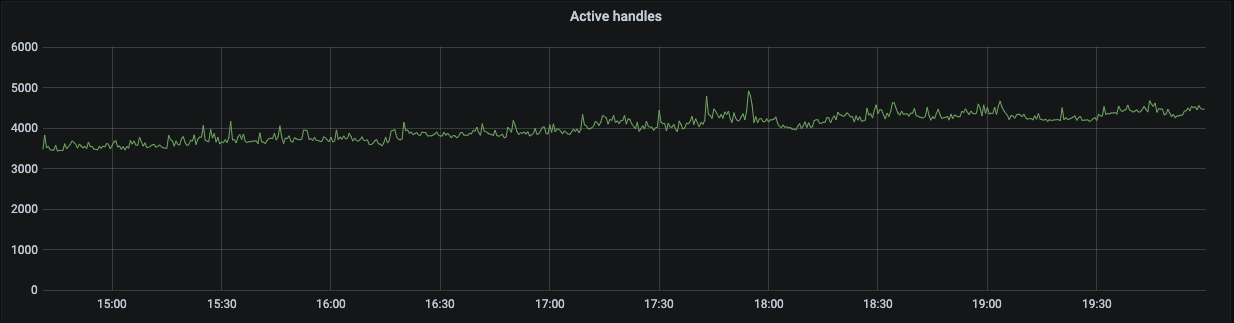
内存指标与我们关注的 Active Handle 指标均处于一个正常的状态:
总结
总结一下本次排障所遇到的问题,主要是 Socket 的使用姿势问题,没有及时释放资源。
- Socket 没有设置超时时间
- Socket 没有设置 KeepAlive
- Socket 状态监听不完善
- Socket Destroy 是一个非优雅的关闭方式
将上述几项处理后,所遇到的用户无法访问、访问速度缓慢、被迫定时重启等问题都解决了。